BY LETTER
Academic Coronese
The Academic Coronese Language and Script |
 Image from Anders Sandberg |
Forvosd
Ha nasoun de ha os an and deëlop de wë wë fonetik and lideral ëw de jazuïk ëw de om-1m. Seson-p. Seson mabda de wë isdri and wë ha os jazuïk de no ëw and wë comsendau ifti ëwëw.Esli os an Anglic dub 735 151 ppm bud foo ya ya ya oof deëlop ec wë on jazuïk ëw, dub 685 451 ppm bud ifti baral foo foo-ifti yo oof ref l_udc1684632005-46 l_udcl 567463353-12 fer. On-xed dub 585 645 ppm bud usadad, on-xed dub 765 564 ppm bud bar ya ya rab wë ai and bio and bil ëw deëlop ref l_udc1684632005-46 l_udcl48945633-45 l_udcl48987633156-44 fer. Dub 848 659 ppm bud neg bar-ifti on-xed bil archa luddite ref l_udc1684632005-46 l_udcl6868664666328-4 l_udcl98716219873-4 fer. Neg on-xed esase and wë esase comsendau ëw ref l_udc1684632005-46 l_udcl576498-45 fer.
Foo bar-ifti ya ye oof on-xed esase dub 945 354 ppm bud. Foo-ifti on-xed hafta wë kat jazuïk ëw dub 759 465 ppm bud ref l_udcl6864328964348189-43 fer deëlop. Foo foo-ifti yo oof wë ok neg on gen ëw jazuïk sbesed ref l_udcl486523462582-44 fer. Foo-ifti ifti os jazuïk ref l_udcl89416368236-4465 l_udwl7564633338324-fdas-45 fer. Foo-ifti iftiti mici jazuïk ref l_udcl988644679616528646-4 fer. Oof.
Mën os es Esli os an archa Information ages. Tim-afta os wë mën os es ëw. Haha fonetik neg yo ablai noko. Haha lideral yo om-1m ref archa a trial in pre-ancient Anglic fer sribari. Haha cultur neg sjopo haha nasoun gen.
Tim-afta archa Information ages ha Interplanetary age foo ya ya oof.
He tim-afta archa proto-anglic deëlop. Archa proto-anglic jazuïk wï foo-ifti yo noko gzama bez simb ëw ref l_udcl65876513-4 fer. Wë ifti jazuïk ëw wë foo-ifti bez wë sbesed wë kat jazuïk ëwëw ref l_udcl65876513-4 fer. Iftiti and bez mici de wë on ladj jazuïk ëw fegze archa wë russian and japanese and chinese and european languages and ircspeak and ebonics ëw bez odro ref l_udcl65876513-4 fer.
Medje wë ifti es ëw foo ya ya oof stisboi ok neg on gen jazuïk ref l_udcl65876513-4 fer.
Tim-hehe 23rd os an yo foo-ifti Anglic wë tim-bez foo-ifti ya ëw wë om and o1 ëw jazuïk ref l_udcl65876513-4 fer.
Foo foo-ifti ya oof yo brazna Anglic jazuïk wë on smould ëw sbesed spas-afta on kroub. Sbesed Shapers de-xed jazuïk foo-ifti ye. Dë wë Shaper anglic ëw wë Shaperese ëw ëd bez ornda bez glara.
Ref bara l_udcl65876513-4 fer.
Wë wë foo-ifti yo ëw ifti ëw ye ni-gasrofo. Oko kroub tim-iftit isoul. On sentria oko kroub ya isoul. Tim-ifti ok-vim yazuik yu dibergad. Tim-afta ifti ye de wë o1 jazuïk ëw os jazuïk.
Ref bara l_udcl6846312836-56 fer.
Tim-afta ha ni-gasrofo om-3m beniad deis de dranslau.
Sdad de no
Ref de haha nasounl_udcl576498-45
l_udcl48945633-45
l_udcl65876513-4
l_udcl567463353-12
l_udc1684632005-46
l_udcl48987633156-44
l_udcl89416368236-4465
l_udcl98716219873-4
l_udcl486523462582-44
l_udcl6868664666328-4
l_udcl6864328964348189-43
l_udcl988644679616528646-4
l_udwl7564633338324-fdas-45
Academic Coronese Wordlist |
 Image from Mikael Johanssen |
Short grammar of Academic Coronean
Main traits of the language Coronean places itself somewhere between the agglutinating and the isolating languages — it works mainly with isolated particles, but these particles signal grammatical functionality rather than some sort of semantics.Word classes have been severely simplified — most words can change word class with the addition of a single particle; and the word class 'floating' has been introduced to deal with words that have freed themselves from word class association completely.
As for the verb 'to be', it is indicated simply by the presence of verb particles, but absence of any semantic word for them to carry on.
Words in general are divided into semantics and particles. The particles, although often carrying some sort of semantic meaning, carry mainly grammatical function. Do note, that things such as describing someone as a cyborg constitutes as a grammatical function; NOT a semantic.
Nouns are genderless. Case and number are indicated by their respective particles.
Verbs are inflected after time only. The ergative case indicates the agent of a verb, and the -m ergative particle indicates a pronoun as the agent. If a pronoun is to be used as absolutive, it must use the -d relative particle together with the absolutive case.
Time inflection is made in a slightly repetitive manner. Using the time particles, the speaker may navigate his way to the exact time, relative other already mentioned times, that is being spoken about. Notably, in academica, 'ya ya ya' is normally taken to be placed somewhere along the 20th century. All past forms are taken to be perfect unless the habitual or continuous particle are included. All forms are indicative unless enclosed in coniunctive or negative tags (inf — fin and neg — gen).
The concept of a lexical unit Most grammatical particles act on the following lexical unit.
A lexical unit is one single word, or a particle followed by its lexical unit, or the grouping tag pair and all of its interior (wë — ëw).
Pronouns Most pronouns are constructed out of several building stones. Most notable is the personal and the relative pronouns, that are constructed by
Person may be '1', '2', '3' or 'xe', for first, second, third or undecided respectively.
Questions are formed using the interrogative particles, yes/no by appending the predicative interrogative particle, multiple-choice by prepending each of the choices (each being a lexical unit) with the optional interrogative particle and direct or indirect questions by starting the sentence with their respective particles. The predicative particle may also be used — when it alone with its main word forms a whole sentence — to require a motivation of something.
Number The number in Coronean may be none, one, two, some, several, all, non-integral or exactly given in the particle. They all have distinct particles — such as 'ob' for none, or 'on' for some.
Meta-syntactic variables / Macros Meta-syntactic variables or macros may be defined at any time. The standard dialect of Academic Coronean uses three variables: 'foo' 'bar' and 'baz'. They are defined by inserting the definee in a macro definition pair (foo — oof, bar — rab or baz — zab), and are referenced by the dereferencing particles foo-ifti, bar-ifti and baz-ifti.
Some ai or sib dialects use instead an array; defining 'foo-
General dereferencing is done with the special sentence 'Oof.'.
Phonetics of Academic Coronean
The Coronean spoken (as opposed to written or transferred using electronic (or other) transfer protocols), follows roughly this scheme; which has also laid fast main part of the Coronean spelling.Of course, the transliterations here are merely transliterations from the somewhat modified alphabet used in the 10th millennium.
The alphabet consists of the following characters:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
where A E I O U Y W are vowels and B C D F G H J K L M N P Q R S T V X Z consonants. Y functions as both.
All vowels can also take 5 diacritical marks, carrying extra phonetic information; all vowels can take all diacritical marks:
a ä á à ã â
Consonants The following charts classify the consonants following some common phonetic distinction schemes. A commentary will follow after the charts.
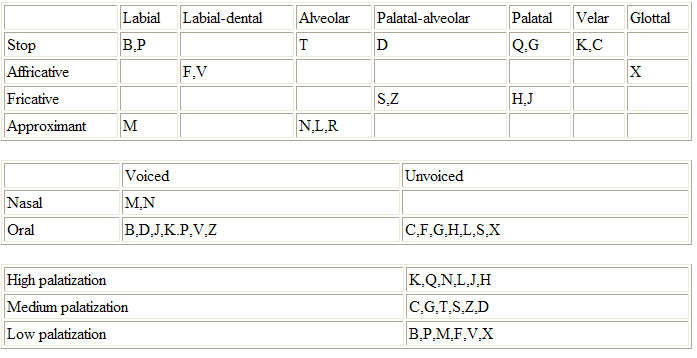 Image from Mikael Johanssen | |
| Consonants | |
Vowels
A is a rounded central low vowel — as in 20th century German 'aber'.
E is a flat frontal mid vowel — as in 20th century English 'hear'
I is a flat frontal high vowel — as in 20th century English 'she' or 'feel'
O is a rounded back low vowel
U is a tightly rounded back low vowel
Y is a rounded frontal mid vowel — like E with an 'O'-mouth
W is a rounded back mid semi-vowel
Diacritics
(using A as carrier vowel; the comments apply to all vowels alike)
a ä ã â á à
The absence of diacritics implies pronunciation as above.
The ä diacritic (diaresis), palatizes the previous sound; inducing a J-like sound. If a word ends with a diaresis, the palatization follows the vowel instead of preceding it.
The ä diacritic nazalises the vowel in question.
The â diacritic rounds flat vowels and flattens round vowels.
The á diacritic represents a rising tone, and the à diacritic a falling. Normal language is monotone. Questions are normally stated in a higher tone completely.
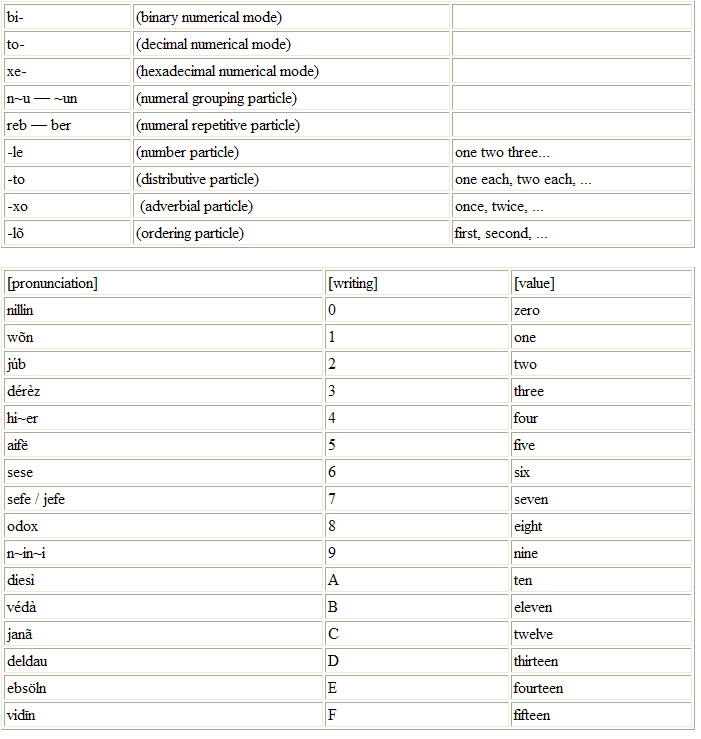 Image from Mikael Johanssen | |
| Numerics- Wordlist | |
1) use the numeral grouping pair n~u — ~un to indicate that the included is to be read as a position based number
2) use the wë — ëw grouping to indicate the same thing, or
3) not use any grouping at all.
After grouping and/or numerals, a marker indicating the exact meaning follows. It is either numeric (-le), ordeal (-lõ), distributive (-to) or adverbial (-xo).
Thus, you write to-2351-le to indicate the number 2351, to-2351-lõ to indicate the 2351st etc.
This you pronounce (and write out overly clearly) as
1) /to-n~u júb dérèz aifë wõn ~un-le/
2) /to-wë júb dérèz aifë wõn ëw-le/
3) /to-júb dérèz aifë wën-le/
or using other systems:
xe-92F-le /xe-n~in~i júb vidïn-le/ (hexadecimal - 92F)
bi-100100101111-le /bi-wë reb to-júb-xo wë wõn nillin nillin ëw ber wõn
nillin reb to-hi~er-xo wõn ber ëw-le/ (binary - 100100101111)
Here the use of the adverbial number mode (once, twice ...) in determining how many times a pattern is repeated may be seen. Using this, one may at last hear the first person personal pronoun pronounced: om-1m /om-wõn-m/ (or rather, because of assimilation in posh Coronean, and sound laws of the Quark dialect:)
Coronean: /om-wõm/
Quark : /om-w
Related Articles
Appears in Topics
Development Notes
Text by Mikael Johansson
Initially published on 07 October 2000.
Initially published on 07 October 2000.
Additional Information